
《圣经》中记载着这样的一则故事:在洗刷世界的大洪水过后,幸存的人们建造了一座通天的高塔并直通天堂,取名为巴别塔。上帝见到这座塔后十分生气,便让世界上的人类都说不同的语言,使人类之间不能沟通,登上天堂的计划也因此失败。

打败当时这些人的原因在于他们不能转化不同语言之间的含义,因此沟通不顺,导致计划破产。但这样的问题放在今天,绝对称不上是一个大问题。
在无数科学家和语言学家日以继夜的努力下,机器翻译(Machine Translation)如今已经可以基本帮助各个国家的人民自由地进行日常交流了。
那么机器翻译究竟是如何产生的?它的原理是什么?
开端
1933年,法国工程师G.B.阿尔楚尼提出了利用机器来进行翻译,提高跨国交流间的效率。为此他还获得了一项机器翻译的专利。

1954年,美国乔治敦大学在IBM公司的帮助下,成功地将60句俄语自动翻译成英语,被认为是机器翻译的开端。
然而好景不长,美国科学院成立的语言自动处理咨询委员会(ALPAC)在1966年公布了一份名为《语言与机器》的报告。该报告直接否定了机器翻译在技术上的可行性。机器翻译的发展从此进入萧条期。

复苏
机器翻译开始复苏并且逐渐崛起的机会,源于一次加拿大环境部的求助。1969年在加拿大确立的《官方语言法》(Official Languages Act)中明确了英语和法语在加拿大占有同样重要的地位,这导致所有的官方通告都必须同时以英语和法语的形式公布。尤其是在天气预报上,如果单单使用人工翻译,那将会是一件极其复杂繁琐的工作。
于是,在1976 年,由加拿大蒙特利尔大学与加拿大联邦政府翻译局联合开发的 TAUM-METEO 系统在当时发挥了重要的作用。
后来随着全球化的趋势逐渐增强,各国的科技公司也发展出更为先进的神经网络机器翻译。纵观机器翻译的历史,我们可以发现机器翻译经历过高潮,也经历过低谷。主要过程大致可以分为三个阶段:规则翻译、统计机器翻译、神经网络翻译。
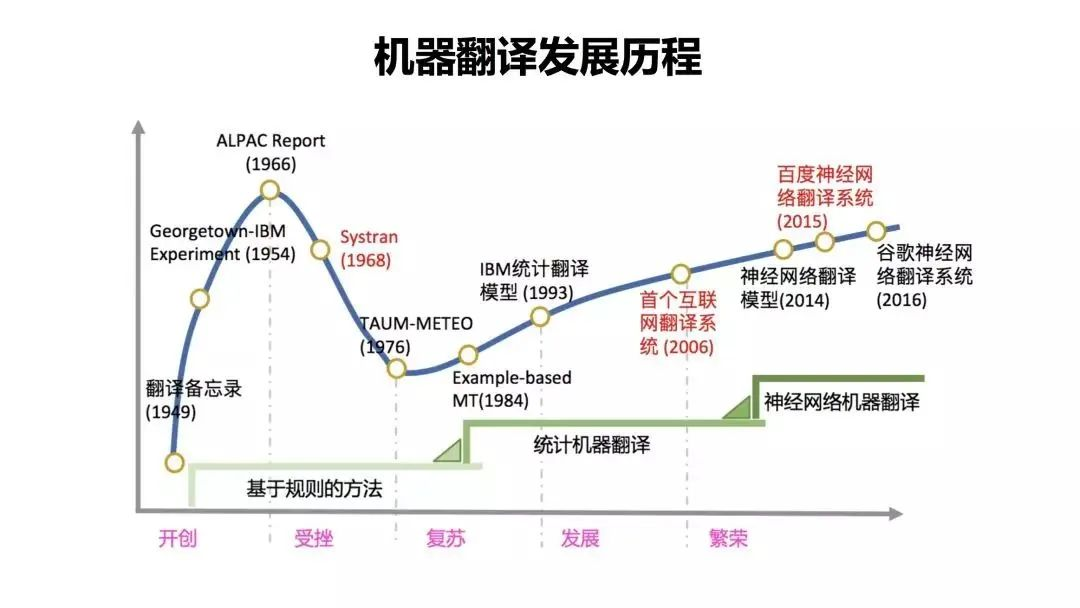
机器翻译的难度
对于任何一段文字的翻译,我们追求的第一要求一定是精准,所以我们不妨以一个例子来解释:

翻译的本质,即是将一种源语言转化成为目标语言。但在这其中,也有着大量的困难存在。
首先就是对于词语的选择,在任何一门语言中,一定都少不了许多的同义词,这是千百年来人们为了使语言的表达更加多样化所创造出的成果。但对于同义词的选择也往往成了影响翻译精准度最大的因素。
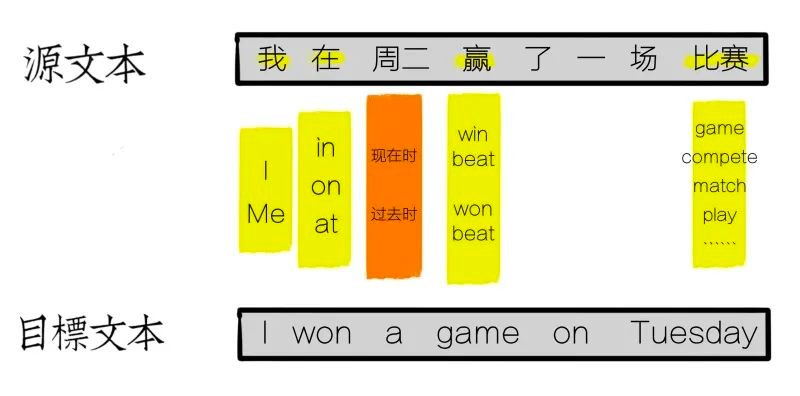
除此之外,机器必须清楚地知道在星期[tuesday]前必须要用介词[on];[了]字表示已经发生过的事情,因此整句用过去时态;同时,机器翻译还必须知道当[game]作宾语时,[赢]必须翻译成[win]来作谓语。
另一个困难就是对语序的排列。由于语言不同的发展过程,不同语言的语序也有所不同,例如[在周二]这个时间状语,中文习惯放在动词前,但在英语中则习惯放在宾语后。
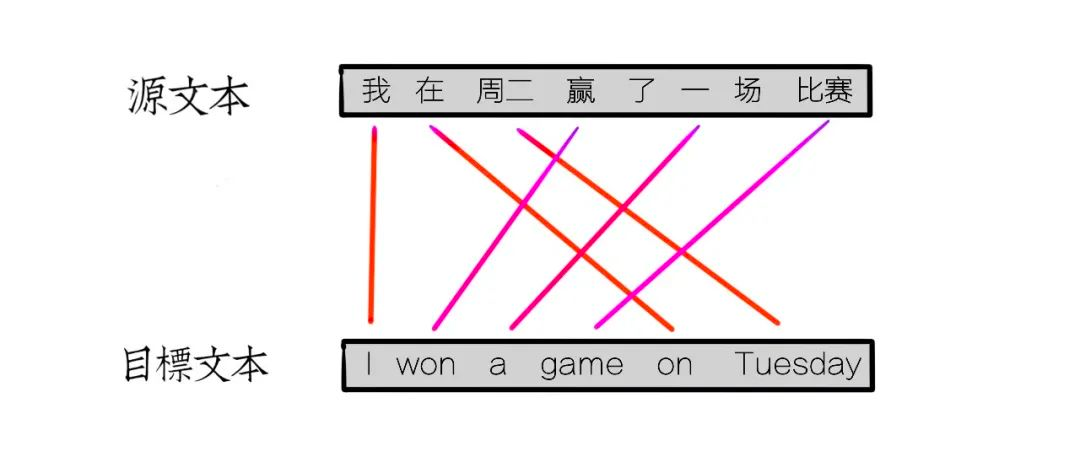
另一个例子,中文的句子结构是“主谓宾”,而日语的句子结构则是“主宾谓”。例如中文的[我喝水]翻译成日文的顺序就应该是[我水喝]。在更复杂一点的句子中,语序的调整就会更加复杂。
第三困难就是数据的稀缺,在不同国家,由于国家间关系发展的不均衡和不同国家世界地位不同,本国语言对于该语言的数据资源数量也不同。
在机器翻译领域,更多的数据就意味着更多可以用来训练机器的资源。在非常少的数据上,想要训练出一个好的系统是非常困难的。
机器翻译的工作方式
在前文中我们提到过机器翻译一共经历了三个阶段,不同阶段的区别主要是机器翻译的工作方式不同。
规则机器翻译
规则法机器翻译的范例包含了转化法(transfer-based)、中间语法(interlingual)、以及辞典法(dictionary-based)机器翻译 。
转化法
转化法顾名思义,就是直接对于每个词语进行点对点的翻译。在当时,机器翻译需要人工撰写规则,规则告诉机器遇到一个词后翻译成为另一个词。同时这个词在新的句子中承担什么成分。
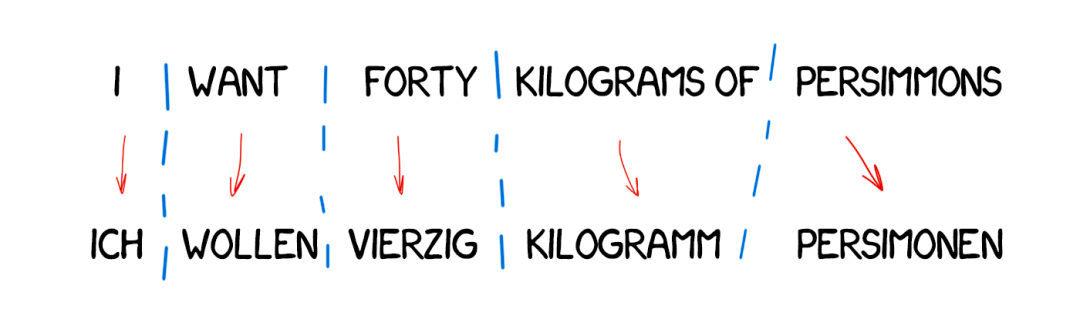
这种方法有一个显著的缺点,那就是需要耗费大量的人工去不断地输入规则,手动帮助机器学习。工作周期长、成本高,还有可能会因为不同规则之间的冲突导致机器死机。
词典法
辞典法则是转化法的进一步升级,直接利用机器在辞典中寻找源语言中的每一个词语对应出目标语言的词语并组成句子。
中间语法
正如前文提到过的,并不是任意两种语言之间都有大量的数据去训练机器。面对稀少的资源时,机器翻译会挑选一门和两门语言都接近的“中间语”。
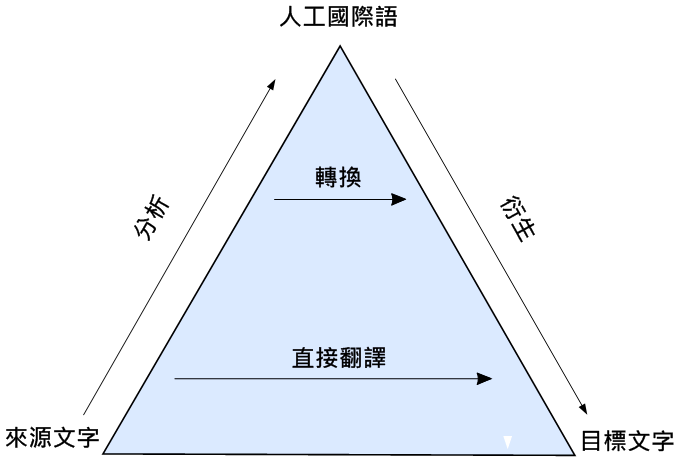
例如现在机器需要将A语言翻译成C语言,但是现成的可供参考的AC互译资料实在太过稀少,但是恰好有这样一门B语言,在AB互译和BC互译上都已经积累了不少的数据,机器翻译此时就可以先将A语言翻译成B语言,再将B语言翻译成C语言。
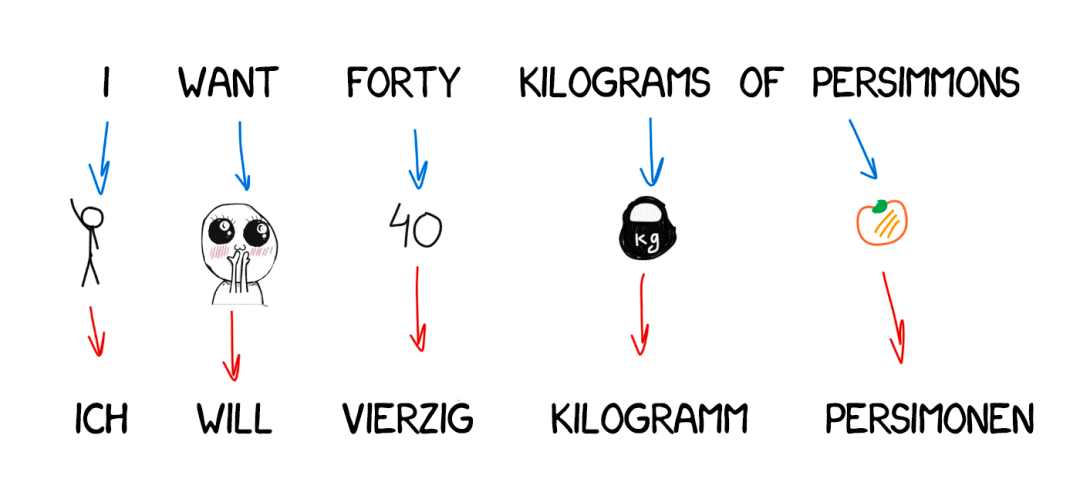
统计翻译
统计翻译出现于上世纪九十年代,具体方法是对机器翻译系统进行了一个数学建模,建模的目的,是用来让机器在翻译时通过具体的概率来判断这样翻译到底对不对。
举个例子,下图中利用了统计机器翻译翻译了[我在周日看了一本书]这句话。在此之前,机器已经经过平行语料和单语语料的训练。
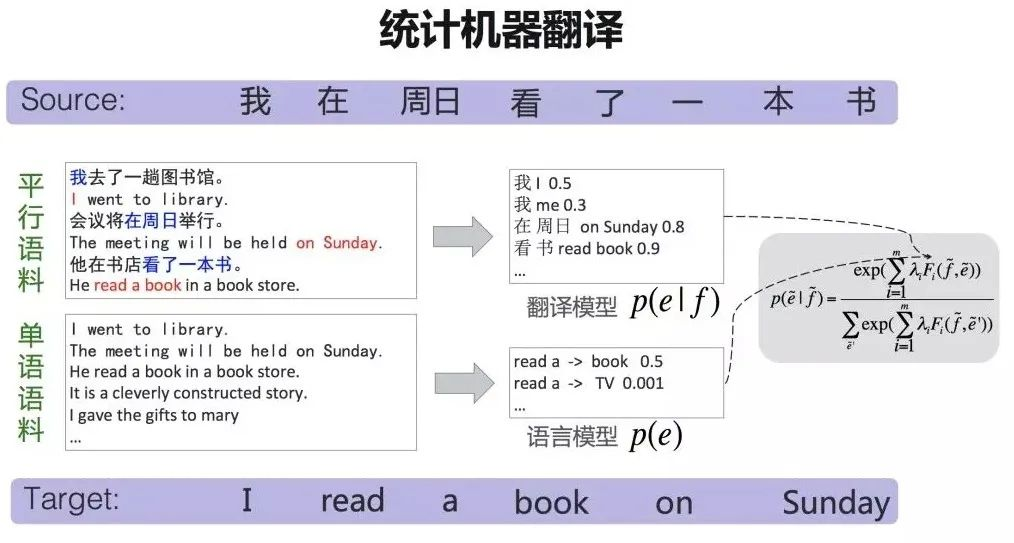
平行语料指的就是现成的大量的已经完成互译的句子,机器翻译由此可以知道具体的一些词汇该对应哪些另一种词汇。在大量的训练中,机器之间发现了出现[我]字时,用[I]的正确率大约是0.5,而当出现[在周日]时,使用[on Sunday]的正确率能够达到0.8。机器就会记住这些并在下次翻译的时候更倾向于使用正确率高的词汇。
单语语料则是大量的目标语言的表述正确的句子,主要用来帮助机器判断语序和词语选择,例如[read a]后面跟[book]作宾语的正确率为0.5,但如果跟[TV]时,正确率只有0.001,显而易见,[read a]后面是不能跟[TV]的。这便是机器利用统计学习的过程。
神经网络机器翻译
神经网络翻译是近年来急速崛起的一种机器翻译模式。既然叫做神经网络,那就说明它还是存在一定的仿生学原理的。
在我们的大脑中,神经元负责信号的储存与传递信息,在机器翻译的神经网络中,同样有着类似的结构。
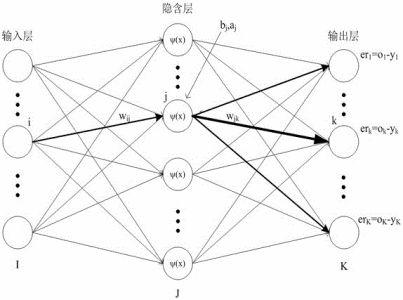
机器神经网络一般会包含三个结构,分别是输入层、隐含层、和输出层。
利用神经网络的第一步就是训练神经网络,也叫做机器学习。在最开始的时候,神经网络什么也不知道,需要在输入层输入大量的信息来“教会”神经网络。
举个例子,例如我们要翻译“我在周二赢了一场比赛。”成英语,我们会将所有表示时间、表示[我]、表示[赢]的英语单词都放入输入层。输入层会向不同的隐含层派发一种排列组合的可能性,隐含层再将得到的翻译结果在输出层输出。通过对比输出层的答案与这句翻译正确的答案,神经网络就可以确定出在什么时候使用什么词语更合适了。
在训练初期,工程师们会利用大量现成的互译资源来训练神经网络,神经网络会成千上万次的训练中满满积累“经验”,从而进化成一个成熟的翻译系统。
机器翻译的出现无疑是更加推进了全球化的发展,在可预见的未来,机器翻译持续为人类社会发展作出更大的贡献。
参考资料
https://zh.wikipedia.org/wiki/人工神经网络
https://www.zhihu.com/question/22553761
https://zh.wikipedia.org/wiki/机器学习
adacheng.github.io
http://www.duodaa.com/blog/index.php/archives/1075/


Comments